Week 9: Limitations

Welcome to Week 9, the penultimate entry in this series (and normally the “calm before the storm” week at Stanford). In this article, I thought I would discuss some general gripes I had with Rust as well as specific limitations that I encountered.
Sometimes bleeding edge really does mean bleeding
The biggest issue I encountered with Rust is in the async department. One of the primary goals of my development this quarter was building a way to separate the frontend GUI from the backend data source providing the logging details and metadata. This would allow a server with a larger memory pool to be able to load a multi-gigabyte log into memory for quick access but leave the frontend with a smaller memory footprint, small enough to be quickly loaded as a wasm web-app. This meant creating a datasource that was able to make HTTP requests to fetch data. Easy enough, right? Rust has plenty of production-ready networking libraries like actix (our server framework), reqwest (our initial frontend framework), tokio, hyper, or even the built in http module.
I quickly scaffolded out a prototype implementation of our DataSource trait (keep this word in mind) that would simply make an HTTP request, and then serialize the response into our data types using the serde package. We utilized the blocking feature of reqwest to create a synchronous HTTP request. This should not be utilized for a real world workload for multiple reasons:
Since we only have a single thread in our application, any blocking requests we make will stall all other code from running, including the renderer that is responsible for generating the next frame.
Users with a slow internet connection would experience multi-second lag between each frame that made a request, and there are many requests! ❌ Unacceptable solution ❌
I only tested the client/server dimension of our app through localhost which essentially provides a 0-latency, infinite bandwidth fabric between services, I experienced simultaneous frame renders that I couldn’t distinguish from the data-native version of the app.
Given this situation, it made since to try to implement an async approach to data loading. Sure enough, all the HTTP libraries already use the async approach by default (blocking was a feature I added), so it made since for a datasource to produce a Rust Result which is similar to a Promise in JavaScript. However, as soon as I tried to return a Result, I got a blaring error from the compiler: error[E0706]: trait fns cannot be declared async
Sure enough the official docs confirmed this:
Currently, async fn cannot be used in traits on the stable release of Rust.Ouch. I quickly looked for workarounds but the two options were either:
- use a hacky external dependency with a macro
#[async_traitto apply a wrapper to the trait functions. - Upgrade to the
nightlyversion of the rust toolchain, which has just added (November, 2022) support for async functions in traits.
The second option seems good right? Async is relatively new for Rust so it would make since that the core developers are still working on supporting everything. However there was one major caveat: If we apply this new toolchain and its new #![feature(async_fn_in_trait)] macro, we wouldn’t be able to create a dyn DataSource object, which is a way of telling the compiler that the size of a trait is not known at compile time. To be able to apply dyn, a trait must be “Object-safe”, but the new macro voided the object safety that our app needed to function. It seems like the bleeding edge of Rust killed this feature, (for now).
Wasm Troubles
You might ask:
“Well synchronous isn’t that bad, right? It still WORKS!”
Sure, however I ran into an immediate issue when trying to compile prof-viewer with the target platform being WebAssembly.
When compiling I got vague errors of HTTP libraries missing or using unsupported and after doing some quick research, I immediately saw why: Many Rust libraries only support their async functions in Rust through the WASI interface. This is because the WASI interface enables HTTP through the fetch interface in native JavaScript. If you recall, fetch is an asynchronous function, and therefore is also an async function when ported through WASI. Ouch, I am back at the same problem I walked through above. Well maybe there is a way I could spin up a separate thread to handle the async request, and then apply the returned response in an independent fashion from the synchronous render thread. The issue: threads are complicated/non-existent in Rust as well. The traditional idea of a thread does not exist at all in Rust. In JavaScript, the tangential idea of a thread is a “web worker” which enables asynchronous execution of code, independent from the main JS thread. This is supported through the WASI interface, but provides an extremely complicated and low-level abstraction for developers trying to integrate this into their WASM-compatible codebase.
For example, the simplest web-worker WASM example I could find (source: https://www.tweag.io/blog/2022-11-24-wasm-threads-and-messages/) is 4 months old (this is also bleeding edge for WASM)
// A function imitating `std::thread::spawn`.
pub fn spawn(f: impl FnOnce() + Send + 'static) -> Result<web_sys::Worker, JsValue> {
let worker = web_sys::Worker::new("./worker.js")?;
// Double-boxing because `dyn FnOnce` is unsized and so `Box<dyn FnOnce()>` is a fat pointer.
// But `Box<Box<dyn FnOnce()>>` is just a plain pointer, and since wasm has 32-bit pointers,
// we can cast it to a `u32` and back.
let ptr = Box::into_raw(Box::new(Box::new(f) as Box<dyn FnOnce()>));
let msg = js_sys::Array::new();
// Send the worker a reference to our memory chunk, so it can initialize a wasm module
// using the same memory.
msg.push(&wasm_bindgen::memory());
// Also send the worker the address of the closure we want to execute.
msg.push(&JsValue::from(ptr as u32))
worker.post_message(&msg);
}
#[wasm_bindgen]
// This function is here for `worker.js` to call.
pub fn worker_entry_point(addr: u32) {
// Interpret the address we were given as a pointer to a closure to call.
let closure = unsafe { Box::from_raw(ptr as *mut Box<dyn FnOnce()>) };
(*closure)();
}
Followed by an equivalently opaque, polyfill-esque JavaScript code to import the WASM binding:
importScripts("./path/to/wasm_bindgen/module.js")
self.onmessage = async event => {
// event.data[0] should be the Memory object, and event.data[1] is the value to pass into child_entry_point
const { child_entry_point } = await wasm_bindgen(
"./path/to/wasm_bindgen/module_bg.wasm",
event.data[0]
)
child_entry_point(Number(event.data[1]))
}
Only to imitate the native version of channels in Rust (which is the traditional way of sharing messages across multiple threads):
let (to_worker, from_main) = std::sync::mpsc::channel();
let (to_main, from_worker) = std::sync::mpsc::channel();
spawn(move || { to_main.send(from_main.recv().unwrap() + 1.0); });
to_worker.send(1.0);
assert_eq!(from_worker.recv().unwrap(), 2.0);
Yikes! Hundreds of lines of low-level code simply to share an int between JavaScript and Rust asynchronously. The two kickers? You can’t code yourself out of this situation. First, you must compile your Rust project with many extra flags:
RUSTFLAGS="-C target-feature=+atomics,+bulk-memory,+mutable-globals" cargo build --target=wasm32-unknown-unknown --release -Z build-std=panic_abort,std
Then, you must
configure your web server with some special headers, because shared WASM memory builds on SharedArrayBufferThis train of requirements doesn’t seem practical for your average Rust developer to have to juggle on top of the many other components of their stack they have to understand.
While these are my main roadblocks when working on this project, I had many smaller speed-humps with the Rust compiler. For example:
Some expressions like some_func(another_funcs_return()) would give errors, saying that the value returned from another_funcs_return would be out of scope before the function returned. I would have to move this code into something like
let val = another_funcs_return();
some_func(val);
to satiate the compiler. While I am sure the compiler has a valid reason for this that is beyond my knowledge, it seems odd that the compiler forces this level of verbosity on developers.
I also ran into issues with lifetimes and mutexes. This is because the idea of a pointer is more opaque in Rust, as everything in Rust is abstracted into references and lifetimes. In this way, I wasn’t able to easily pass data between functions in different threads as I would have liked to.
Again, there is probably a good reason the compiler was complaining, but the solution as a beginner Rust developer was not obvious and seemed like a roadblock at times.
My last gripe has to do with the disk space required for development. I was extremely happy to hear about Yarn's Plug N' Play functionality that eliminates the need for node_modules/ because that would make a large chunk of repeated downloads and files for each NodeJS project I would work on. Cargo uses a similar structure to the Plug N' Play feature that creates a global environment cache for pacakges. This keeps directories clean and backups simple, however, I noticed that debug builds with Rust made node_modules look TINY.
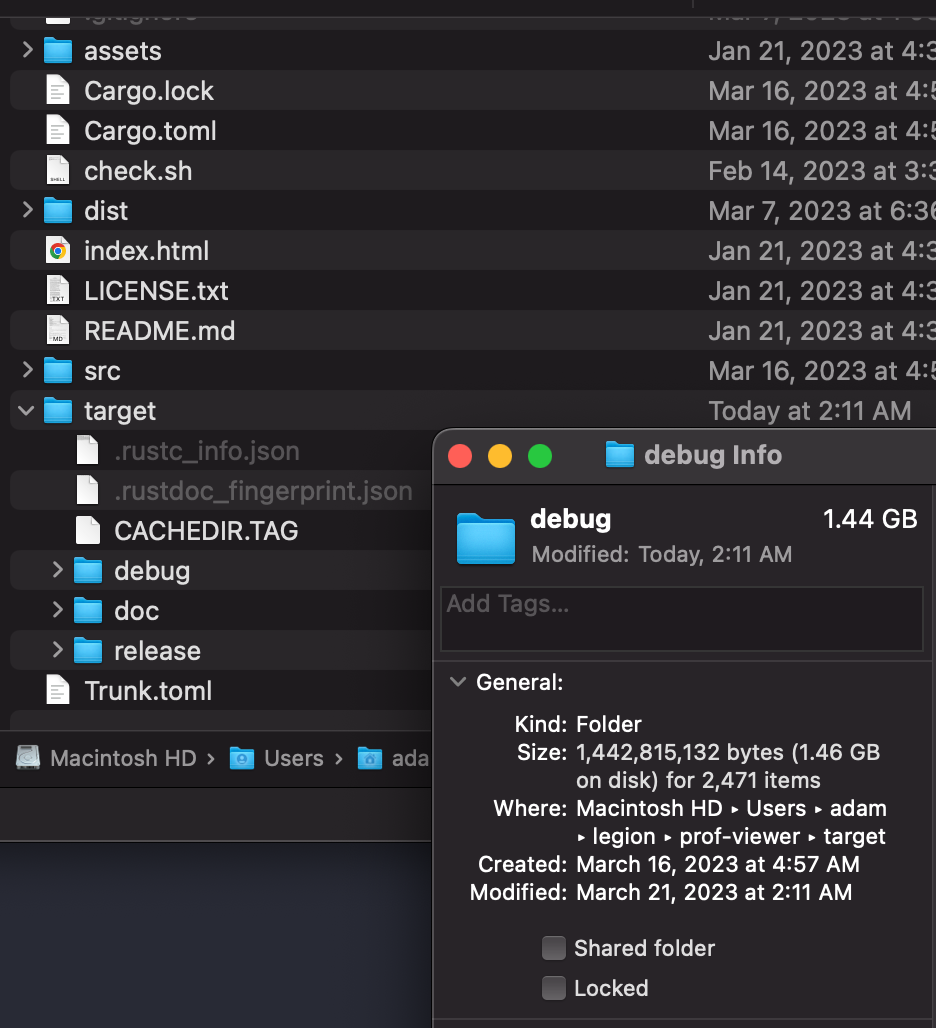
A debug build would take about 1.5 GB for a mid-size project and a release build would be about 700 MB. If I were to be working on multiple projects simultaneously, my already filled-to-the-brim 256GB M2 Macbook Air would be complaining constantly. To solve this, you can easily run a cargo clean in each project. Or just get more storage (I am too cheap to pay $200 for 256 more gigs of storage). I wonder what the break down of those files are, but thats a topic for another post.